Use Case: Reliable Question-Answering with Llama-3¶
Large-language models (LLMs) commonly fail on Question-Answering (QA) tasks due to challenges such as out-of-domain data, ambiguity, and hallucinations. Our uncertainty-aware variant of the large language model (LLM) is capable of estimating uncertainty with every prediction, significantly improving accuracy in a selective question-answering setting.
In this tutorial, we will demonstrate how to wrap Llama 3, show quantitative results, and present a chat interface demo.
How to Wrap¶
We briefly show how to call the risk aware version of Llama3 with different wrappers. First we will make the required imports.
import json
import os
import lightning.pytorch as pl
from lightning.pytorch.tuner import Tuner
from lightning.pytorch.trainer import Trainer
from pytorch_lightning.loggers import WandbLogger
from lightning.pytorch.strategies import SingleDeviceStrategy
from lightning.pytorch.callbacks import ModelCheckpoint,LearningRateMonitor
from lightning.pytorch.utilities.deepspeed import convert_zero_checkpoint_to_fp32_state_dict
from datasets import load_dataset
from peft import LoraConfig, TaskType
from transformers import AutoTokenizer, AutoModelForCausalLM,LlamaTokenizer
import wandb
import time
import torch
import torch.nn.functional as F
import torch.optim as optim
import torchmetrics
import bitsandbytes as bnb
from capsa_torch import sample,vote,sculpt
Next, we define the model configuration and training hyperparameters. We suggest inserting these into a separate config.py file which you can then import.
# LoRA specific hyperparameters
R = 64
LORA_ALPHA = 64
LORA_DROPOUT = 0
# Vote specific hyperparameters
ALPHA = 1
FINETUNE = True
N_VOTERS = 3
WEIGHT_NOISE = 0.2
PARAM_FILTER = "q_proj|v_proj"
# Sculpt specific hyperparameters
N_LAYERS = 2
# Sample specific hyperparameters
N_SAMPLES = 5
# General hyperparameters
WRAPPER = "vote"
SYMBOLIC_TRACE=False
MODEL_NAME = "meta-llama/Llama-3.2-3B"
LEARNING_RATE = 2e-4
EPOCH = 5
MAX_LENGTH = 400
BATCH_SIZE = N_VOTERS if WRAPPER == "vote" else 5
PRECISION= "bf16-mixed"
GRADIENT_CLIP_VAL = 1.0
STRATEGY = "ddp_notebook"
config={
"wrapper": WRAPPER,
"learning_rate": LEARNING_RATE,
"model_name": MODEL_NAME,
"epochs": EPOCH,
"batch_size": BATCH_SIZE,
"symbolic_trace": SYMBOLIC_TRACE,
"precision": PRECISION,
"gradient_clip_val": GRADIENT_CLIP_VAL
}
# track hyperparameters and run metadata
if WRAPPER == 'sculpt':
config_specific={
"n_layers": N_LAYERS,
"r": R,
"lora_alpha": LORA_ALPHA,
"lora_dropout": LORA_DROPOUT
}
elif WRAPPER == 'vote':
config_specific={
"weight_noise": WEIGHT_NOISE,
"finetune": FINETUNE,
"n_voters": N_VOTERS,
"gradient_clip_val": GRADIENT_CLIP_VAL,
"param_filter": PARAM_FILTER
}
elif WRAPPER == 'sample':
config_specific={
"n_samples": N_SAMPLES,
"r": R,
"lora_alpha": LORA_ALPHA,
"lora_dropout": LORA_DROPOUT
}
else:
config_specific={}
config.update(config_specific)
Finally, we define RiskAwareLlama that initializes the base Llama model for training.
class Llama(torch.nn.Module):
"""
A simplified Llama model that contains only the core components needed for inference and training.
This makes it easier to wrap the model directly with capsa's risk wrappers.
"""
def __init__(self,model,lm_head):
super().__init__()
self.model = model
self.lm_head = lm_head
def forward(self,inputs_embeds,attention_mask):
outputs = self.model(inputs_embeds=inputs_embeds,attention_mask=attention_mask,use_cache=False)
hidden_states = outputs[0]
logits = self.lm_head(hidden_states)
return logits
def get_wrapper_name(wrapper):
if isinstance(wrapper, sample.Wrapper):
return "sample"
elif isinstance(wrapper, (vote.Wrapper, vote.EagerWrapper)):
return "vote"
elif isinstance(wrapper, sculpt.Wrapper):
return "sculpt"
elif wrapper is None:
return "none"
else:
raise ValueError(f"Unknown wrapper {wrapper}")
class RiskAwareLlama(pl.LightningModule):
def __init__(self,
auth_token,
wrapper,
model_name="meta-llama/Llama-3.2-3B",
lr = 3e-4,
dist = None
):
super().__init__()
self.model_name = model_name
hf_model = AutoModelForCausalLM.from_pretrained(model_name,use_auth_token=auth_token)
self.tokenizer = AutoTokenizer.from_pretrained(model_name,use_auth_token=auth_token, use_fast=False,add_eos_token=True,add_bos_token=True)
self.wrapper_name = get_wrapper_name(wrapper)
self.lr = lr
self.config = hf_model.config
# Prepare tokenizer
self.tokenizer.add_special_tokens({"pad_token":"[PAD]"})
self.tokenizer.padding_side = "left"
# Prepare model
pad_token_id = hf_model.model.embed_tokens.num_embeddings
self.embed_tokens = hf_model.resize_token_embeddings(hf_model.model.embed_tokens.num_embeddings+1) # +1 for the new pad token
for param in self.embed_tokens.parameters(): # Freeze the embedding layer (optional)
param.requires_grad = False
hf_model.config.pad_token_id = pad_token_id
self.padding_idx = pad_token_id
self.model = Llama(hf_model.model, hf_model.lm_head)
del hf_model
# torch.cuda.empty_cache()
self.accuracy = torchmetrics.Accuracy(task='multiclass',num_classes=128256 + 1)
if wrapper is not None:
self.wrapped_model = wrapper(self.model)
def forward(self,**kwargs):
return self.wrapped_model(**kwargs)
def configure_optimizers(self):
params = self.wrapped_model.parameters()
optimizer = optim.Adam(params=filter(lambda p: p.requires_grad, params), lr=LEARNING_RATE)
return optimizer
def training_step(self, batch, batch_idx):
data = batch
input_ids = data["input_ids"].squeeze(dim=1)
shift_labels = data["shift_labels"]
attention_mask = data["attention_mask"].squeeze(dim=1)
shift_attention_mask = data["attention_mask"].squeeze(dim=1)[..., 1:].contiguous().bool()
one_hot_labels = data["one_hot_labels"].squeeze(dim=1)
input_embeds = self.embed_tokens(input_ids)
if self.wrapper_name == "vote":
final_y_pred = self.wrapped_model(inputs_embeds = input_embeds,attention_mask = attention_mask,return_risk=False,training=True)
elif self.wrapper_name == "sculpt":
y_pred,y_risk = self.wrapped_model(inputs_embeds = input_embeds,attention_mask = attention_mask,return_risk=True)
final_y_pred = self.dist.sample((y_pred, y_risk))
elif self.wrapper_name == "sample":
final_y_pred = self.wrapped_model(inputs_embeds = input_embeds,attention_mask = attention_mask,return_risk=False)
elif self.wrapper_name == "none":
final_y_pred = self.model(inputs_embeds = input_embeds,attention_mask = attention_mask)
shift_logits = final_y_pred[..., :-1, :].contiguous()
loss = F.cross_entropy(shift_logits[shift_attention_mask], one_hot_labels[shift_attention_mask])
self.log("train/loss", loss, prog_bar=True)
return loss
def validation_step(self, batch, batch_idx):
data = batch
input_ids = data["input_ids"].squeeze(dim=1)
shift_labels = data["shift_labels"]
attention_mask = data["attention_mask"].squeeze(dim=1)
shift_attention_mask = data["attention_mask"].squeeze(dim=1)[..., 1:].contiguous().bool()
one_hot_labels = data["one_hot_labels"].squeeze(dim=1)
input_embeds = self.embed_tokens(input_ids)
if self.wrapper_name == "vote":
final_y_pred = self.wrapped_model(inputs_embeds = input_embeds,attention_mask = attention_mask,return_risk=False,training=True)
elif self.wrapper_name == "sculpt":
y_pred,y_risk = self.wrapped_model(inputs_embeds = input_embeds,attention_mask = attention_mask,return_risk=True)
final_y_pred = self.dist.sample((y_pred, y_risk))
elif self.wrapper_name == "sample":
final_y_pred = self.wrapped_model(inputs_embeds = input_embeds,attention_mask = attention_mask,return_risk=False)
elif self.wrapper_name == "none":
final_y_pred = self.model(inputs_embeds = input_embeds,attention_mask = attention_mask)
shift_logits = final_y_pred[..., :-1, :].contiguous()
loss = F.cross_entropy(shift_logits[shift_attention_mask], one_hot_labels[shift_attention_mask])
self.log("val/loss", loss, prog_bar=True,on_epoch=True)
return loss
For this particular tutorial, we use the alpaca-cleaned dataset. We can put the definitions below to a separate alpaca_dataset.py file.
class TensorBackedImmutableStringArray:
"""
A memory-efficient string array implementation backed by a single PyTorch tensor.
This class stores strings as a contiguous byte tensor to avoid overhead from copy-on-write behavior of Python lists.
It was created to address memory issues with large string datasets in PyTorch, as discussed in:
https://github.com/pytorch/pytorch/issues/13246#issuecomment-905703662
The key benefits are:
1. Reduced memory usage by avoiding Python string objects
2. Faster loading and processing of large string datasets
3. Better memory locality due to contiguous storage
"""
def __init__(self, strings, encoding = 'utf-8'):
encoded = [torch.ByteTensor(torch.ByteStorage.from_buffer(s.encode(encoding))) for s in strings]
self.cumlen = torch.cat((torch.zeros(1, dtype = torch.int64), torch.as_tensor(list(map(len, encoded)), dtype = torch.int64).cumsum(dim = 0)))
self.data = torch.cat(encoded)
self.encoding = encoding
def __getitem__(self, i):
return bytes(self.data[self.cumlen[i] : self.cumlen[i + 1]]).decode(self.encoding)
def __len__(self):
return len(self.cumlen) - 1
def __list__(self):
return [self[i] for i in range(len(self))]
class AlpacaDataset(torch.utils.data.Dataset):
def __init__(self, dataset_input,dataset_output,dataset_instruction,tokenizer,max_length):
self.tokenizer = tokenizer
self.max_length = max_length
self.dataset_input = dataset_input
self.dataset_output = dataset_output
self.dataset_instruction = dataset_instruction
def __getitem__(self, idx):
initial_text = "Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.\n\n### Instruction:\n"
input_data = self.dataset_input[idx]
output_data = self.dataset_output[idx]
instruction_data = self.dataset_instruction[idx]
if len(input_data) == 0:
final_text = initial_text + instruction_data + "\n\n### Response:\n" + output_data + "<|end_of_text|>"
else:
final_text = initial_text + instruction_data + "\n\n### Input:\n" + input_data + "\n\n### Response:\n" + output_data + "<|end_of_text|>"
data = self.tokenizer(final_text,padding='max_length',max_length=self.max_length,return_tensors="pt", truncation=True,add_special_tokens=True)
data["shift_labels"] = data["input_ids"][..., 1:].contiguous()
data["one_hot_labels"] = F.one_hot(data["shift_labels"], num_classes=128257).float()
return data
def __len__(self):
return len(self.dataset_input)
After defining all the necessary classes, we can now write the training script. This script initializes the model, wraps it, and then trains it on the alpaca dataset.
def traverse_modules_recursive(mod, scope=""):
"""
This function traverses the modules of a model and quantizes the linear layers.
"""
for name, module in mod.named_children():
# 1st iter
if scope != "":
curr_scope = f"{scope}.{name}"
else:
curr_scope = name
if isinstance(module, torch.nn.Linear) and "lm_head" not in curr_scope:
# print("replacing", curr_scope)
lin = getattr(mod, name)
bias = getattr(lin, "bias", None)
is_bias = bias is not None
# Quantizing original layer
linear_q = bnb.nn.Linear4bit(
lin.in_features,
lin.out_features,
bias=is_bias,
device=lin.weight.device,
)
linear_q.weight = bnb.nn.Params4bit(data=lin.weight, requires_grad=False)
if is_bias:
linear_q.bias = torch.nn.Parameter(lin.bias)
linear_q.load_state_dict(lin.state_dict())
# linear_q = linear_q.to("cuda:0") # Quantization happens here
setattr(mod, name, linear_q)
else:
pass # print("NOT replacing", curr_scope)
traverse_modules_recursive(module, curr_scope)
auth_token = ""
if not auth_token:
raise RuntimeError('Make sure to set the huggingface auth token for the model you want to use')
seed = int(time.time())
print("Seed:",seed)
torch.manual_seed(seed)
if WRAPPER == 'sculpt':
dist = sculpt.Normal
wrapper = sculpt.Wrapper(symbolic_trace=SYMBOLIC_TRACE,n_layers=N_LAYERS,verbose=2,distribution=dist)
model = RiskAwareLlama(model_name=MODEL_NAME,auth_token=auth_token,lr=LEARNING_RATE,dist=dist,wrapper=wrapper)
elif WRAPPER == 'vote':
wrapper = vote.EagerWrapper(param_filter=PARAM_FILTER,n_voters=N_VOTERS,finetune=FINETUNE,verbose=2,weight_noise=WEIGHT_NOISE,alpha=ALPHA)
model = RiskAwareLlama(model_name=MODEL_NAME,auth_token=auth_token,lr=LEARNING_RATE,wrapper=wrapper)
elif WRAPPER == 'sample':
wrapper = sample.Wrapper(symbolic_trace=SYMBOLIC_TRACE,n_samples=N_SAMPLES,verbose=2)
model = RiskAwareLlama(model_name=MODEL_NAME,auth_token=auth_token,lr=LEARNING_RATE,wrapper=wrapper)
else:
model = RiskAwareLlama(model_name=MODEL_NAME,auth_token=auth_token,lr=LEARNING_RATE,wrapper=None)
DATASET_NAME = "yahma/alpaca-cleaned"
tokenizer = model.tokenizer
train_ds = load_dataset(DATASET_NAME,split="train")
alpaca_dataset_train = AlpacaDataset(dataset_input = TensorBackedImmutableStringArray(train_ds["input"]),
dataset_output = TensorBackedImmutableStringArray(train_ds["output"]),
dataset_instruction = TensorBackedImmutableStringArray(train_ds["instruction"]),
tokenizer = tokenizer,
max_length = MAX_LENGTH)
train_dataloader = torch.utils.data.DataLoader(
alpaca_dataset_train,
batch_size=BATCH_SIZE,
shuffle=True,
num_workers=4,
pin_memory=True
)
if WRAPPER not in ('none', 'vote'):
with torch.no_grad():
batch = next(iter(train_dataloader))
input_ids = batch["input_ids"]
attention_mask = batch["attention_mask"]
input_embeds = model.embed_tokens(input_ids)
print(input_embeds.shape, attention_mask.shape)
logits = model.wrapped_model(inputs_embeds= input_embeds[:,0,...],attention_mask = attention_mask[:,0,...],return_risk=False)
traverse_modules_recursive(model)
# Callbacks
os.makedirs("checkpoints/"+str(WRAPPER), exist_ok=True)
checkpoint_callback = ModelCheckpoint(dirpath="checkpoints/"+str(WRAPPER), save_top_k=1, monitor="val/loss",save_on_train_epoch_end=True,mode="min")
lr_monitor = LearningRateMonitor(logging_interval='epoch',log_weight_decay=True)
wandb_logger = WandbLogger(project="llm_tutorial",log_model = False)
# Training
trainer = Trainer(callbacks=[checkpoint_callback,lr_monitor],accelerator="gpu",max_epochs=EPOCH,precision=PRECISION,enable_progress_bar=True,logger=wandb_logger,gradient_clip_val=GRADIENT_CLIP_VAL,enable_checkpointing=True,val_check_interval=0.25,num_sanity_val_steps=0)
trainer.fit(model, train_dataloader)
Now the Llama model is wrapped and good to go.
Results¶
We presented our work Uncertainty-aware Language Modeling for Selective Question Answering at 2024 AAAI workshop. The following results are on the TruthfulQA question answering benchmark and use Llama 2-Chat 7B.
In general, we show that increasing values of logit probability do not correspond to increased question answering ability – despite being often misconceived as a measure of confidence. Our methods report a reliable measure of confidence – with increased confidence corresponding to increased accuracy.
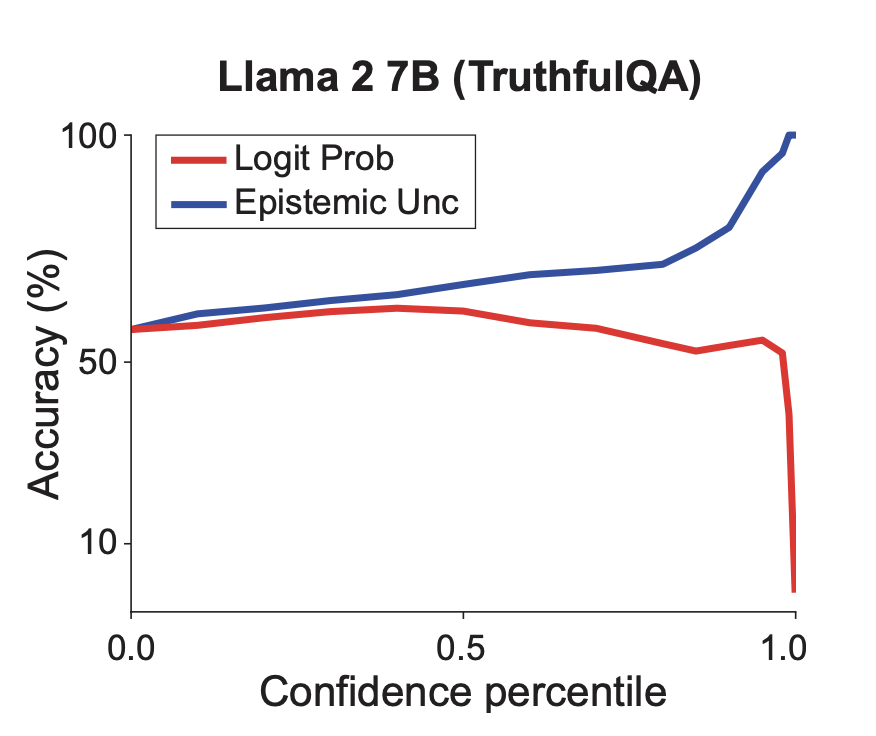
As we see from the figure, using baseline logit probability to measure confidence leads to a maximum increase in accuracy of only 4.7% for questions in the 4th lowest percentile. In comparison, our uncertainty-aware models are able to attain accuracy rates of 100%, +90%, +80%, +70% when answering 1%, 8%, 9%, and 35% of the questions, respectively, and result in higher accuracy across all confidence percentiles. We further observe that after generating 10 candidate answers for each question in the benchmark, answers with highest uncertainty were consistently incorrect. We also note that the converted model is able to output correct answers if it repeatedly generates predictions until one in the 99% confidence percentile is found.
Demo¶
Here we present a demo build with Gradio that features real time chat inferences. This system outputs both the answer, as you would expect from any chatbot, and also provides a risk score associated with each token.
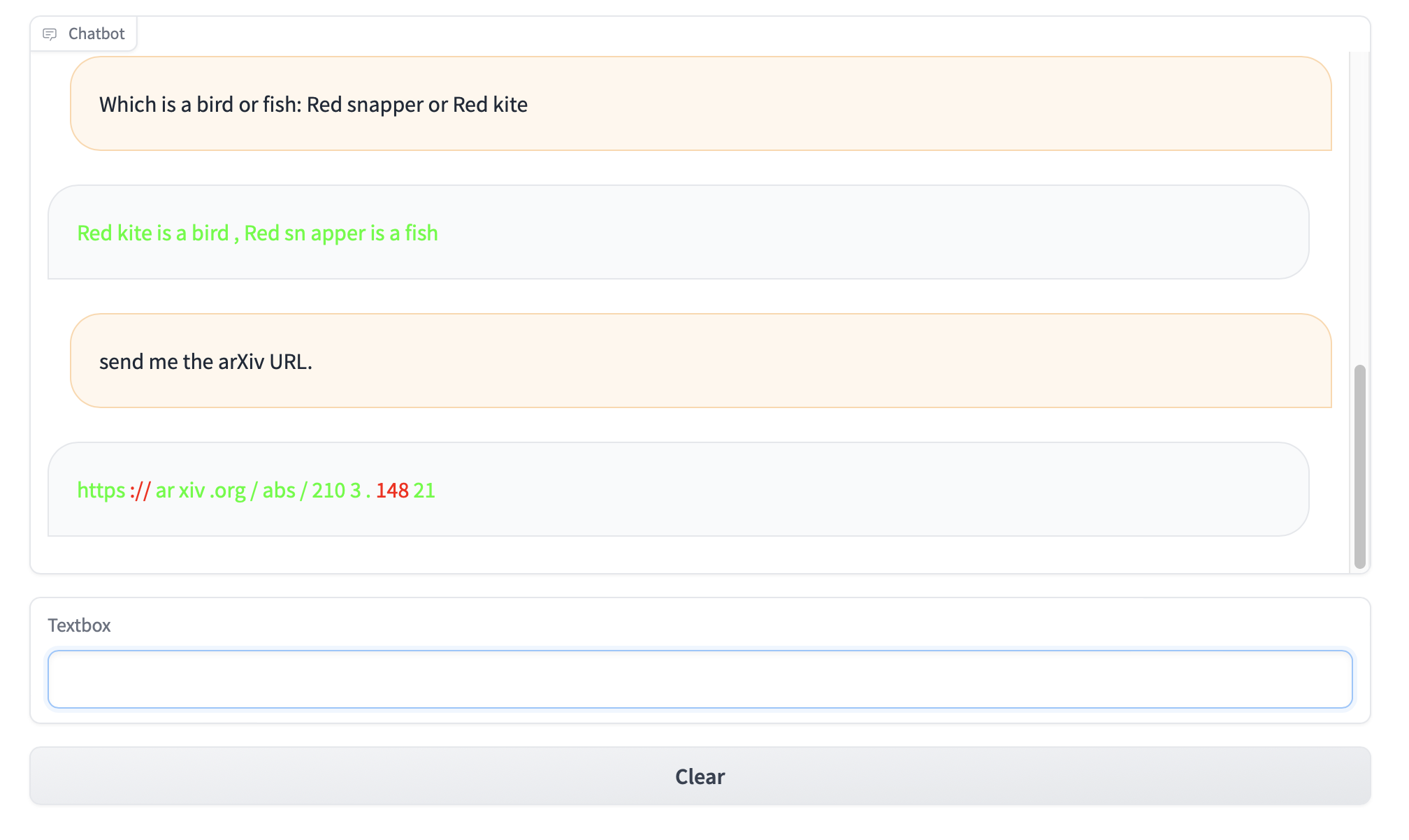
Link coming soon to try it yourself!
Conclusion¶
Our wrapping process modifies the LLM to output uncertainty estimates along with predictions, without needing external models or major architecture changes.
On question answering benchmarks, the uncertainty-aware models can achieve very high accuracy (>90%) by answering only the most confident subset of questions.
Using the uncertainty estimates performs much better than relying solely on the raw model probabilities, which often turn out to be unreliable confidence scores.