Sample Wrapper: Generating CelebA with GAN¶
In this tutorial, we show how to train Generative Adversarial Network (GAN) model on CelebA dataset and wrap it using a Sample wrapper. GAN has two components, one generator to generate new images from random noise, one discriminator to distringuish the synthetic image by generator from the real images, two parts are trained together to genenerate synthetic images that are similar to the training images. CelebA is a collection of celebrity face images. The wrapped model outputs both generated images and risk images, which indicate areas of high uncertainty.
Step 1: Initial Setup¶
This step is universal and dependant to your specific model and dataset you are using. In this tutorial we are covering the steps needed to create a GAN model and load CelebA dataset.
import torch
from torch import nn, optim
from torch.utils.data import DataLoader
import torchvision
import torchvision.transforms as tfms
from torchvision.utils import make_grid
import numpy as np
import matplotlib.pyplot as plt
from tqdm import tqdm
import zipfile
import os
from urllib.request import urlopen
#Configuration parameters for training
dataroot = "."
workers = 2
batch_size = 128
image_size = 64
nc = 3
# Size of z latent vector (i.e. size of generator input)
nz = 100
# Size of feature maps in generator
ngf = 64
# Size of feature maps in discriminator
ndf = 64
imagenet_mean = [0.485, 0.456, 0.406] # mean of the ImageNet dataset for normalizing
imagenet_std = [0.229, 0.224, 0.225] # std of the ImageNet dataset for normalizing
num_epochs = 5
lr = 3e-5
beta1 = 0.5
beta2 = 0.999
def download_file(filename, url):
response = urlopen(url)
size = response.length
CHUNK = 16 * 1024
pbar = tqdm(total=size)
pbar.set_description(f"Downloading {url}")
with open(filename, 'wb') as f:
while True:
chunk = response.read(CHUNK)
pbar.update(CHUNK)
if not chunk:
break
f.write(chunk)
# Download dataset (1.4GB zipped, 1.8GB unzipped)
data_root = "datasets"
base_url = "https://graal.ift.ulaval.ca/public/celeba/"
file_list = [
"img_align_celeba.zip",
"list_attr_celeba.txt",
"identity_CelebA.txt",
"list_bbox_celeba.txt",
"list_landmarks_align_celeba.txt",
"list_eval_partition.txt",
]
# Path to folder with the dataset
dataset_folder = f"{data_root}/celeba"
if not os.path.isdir(dataset_folder):
os.makedirs(dataset_folder, exist_ok=True)
for file in file_list:
url = f"{base_url}/{file}"
if not os.path.exists(f"{dataset_folder}/{file}"):
download_file(f"{dataset_folder}/{file}", url)
zip_file = f"{dataset_folder}/img_align_celeba.zip"
with zipfile.ZipFile(zip_file, "r") as ziphandler:
ziphandler.extractall(dataset_folder)
os.remove(zip_file)
Loading the celebA dataset.
transforms = tfms.Compose(
[
tfms.Resize((image_size, image_size)),
tfms.ToTensor(),
tfms.Normalize(imagenet_mean, imagenet_std),
]
)
train_dataset = torchvision.datasets.CelebA(data_root, split="train", transform=transforms)
dataloader = torch.utils.data.DataLoader(train_dataset, batch_size=batch_size, shuffle=True, num_workers=workers)
# Decide which device we want to run on
device = torch.device("cuda:0" if (torch.cuda.is_available()) else "cpu")
# Plot some training images
real_batch = next(iter(dataloader))
plt.figure(figsize=(8,8))
plt.axis("off")
plt.title("Training Images")
plt.imshow(np.transpose(make_grid(real_batch[0].to(device)[:64], padding=2, normalize=True).cpu(),(1,2,0)))
plt.show()

# custom weights initialization called on ``netG`` and ``netD``
def weights_init(m):
classname = m.__class__.__name__
if classname.find('Conv') != -1:
nn.init.normal_(m.weight.data, 0.0, 0.02)
elif classname.find('BatchNorm') != -1:
nn.init.normal_(m.weight.data, 1.0, 0.02)
nn.init.constant_(m.bias.data, 0)
Creating the GAN module.
# Generator Code
class Generator(nn.Module):
def __init__(self):
super(Generator, self).__init__()
self.main = nn.Sequential(
nn.ConvTranspose2d( nz, ngf * 8, 4, 1, 0, bias=False),
nn.BatchNorm2d(ngf * 8),
nn.ReLU(True),
nn.ConvTranspose2d(ngf * 8, ngf * 4, 4, 2, 1, bias=False),
nn.BatchNorm2d(ngf * 4),
nn.ReLU(True),
nn.ConvTranspose2d( ngf * 4, ngf * 2, 4, 2, 1, bias=False),
nn.BatchNorm2d(ngf * 2),
nn.ReLU(True),
nn.ConvTranspose2d( ngf * 2, ngf, 4, 2, 1, bias=False),
nn.BatchNorm2d(ngf),
nn.ReLU(True),
nn.ConvTranspose2d( ngf, nc, 4, 2, 1, bias=False),
nn.Tanh()
)
def forward(self, input):
return self.main(input)
class Discriminator(nn.Module):
def __init__(self):
super(Discriminator, self).__init__()
self.main = nn.Sequential(
nn.Conv2d(nc, ndf, 4, 2, 1, bias=False),
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(ndf, ndf * 2, 4, 2, 1, bias=False),
nn.BatchNorm2d(ndf * 2),
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(ndf * 2, ndf * 4, 4, 2, 1, bias=False),
nn.BatchNorm2d(ndf * 4),
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(ndf * 4, ndf * 8, 4, 2, 1, bias=False),
nn.BatchNorm2d(ndf * 8),
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(ndf * 8, 1, 4, 1, 0, bias=False),
nn.Sigmoid()
)
def forward(self, input):
return self.main(input)
# Create the generator
netG = Generator().to(device)
# Apply the ``weights_init`` function to randomly initialize all weights
# to ``mean=0``, ``stdev=0.02``.
netG.apply(weights_init);
# Create the Discriminator
netD = Discriminator().to(device)
# Apply the ``weights_init`` function to randomly initialize all weights
# to ``mean=0``, ``stdev=0.02``.
netD.apply(weights_init);
Step 2: Training¶
criterion = nn.BCELoss()
optimizerD = optim.Adam(netD.parameters(), lr=lr, betas=(beta1, beta2))
optimizerG = optim.Adam(netG.parameters(), lr=lr, betas=(beta1, beta2))
#Train the wrapped model
print(f"Training for {num_epochs} epochs")
for epoch in range(num_epochs):
prog_bar = tqdm(dataloader, postfix=dict(epoch=epoch, errD=0, errG=0))
for data in prog_bar:
#Train Discriminator
netD.zero_grad()
real_cpu = data[0].to(device)
b_size = real_cpu.size(0)
label = torch.ones((b_size,), dtype=torch.float, device=device)
output = netD(real_cpu).view(-1)
errD_real = criterion(output, label)
errD_real.backward()
D_x = output.mean().item()
noise = torch.randn(b_size, nz, 1, 1, device=device)
fake = netG(noise)
label.fill_(0)
output = netD(fake.detach()).view(-1)
errD_fake = criterion(output, label)
errD_fake.backward()
D_G_z1 = output.mean().item()
errD = errD_real + errD_fake
optimizerD.step()
#Train Generator
netG.zero_grad()
label.fill_(1)
output = netD(fake).view(-1)
errG = criterion(output, label)
errG.backward()
D_G_z2 = output.mean().item()
optimizerG.step()
prog_bar.set_postfix(epoch=epoch, errD=errD.item(), errG=errG.item())
Training for 5 epochs
100%|██████████| 1272/1272 [01:33<00:00, 13.63it/s, epoch=0, errD=0.315, errG=5.05]
100%|██████████| 1272/1272 [01:34<00:00, 13.51it/s, epoch=1, errD=0.39, errG=3.29]
100%|██████████| 1272/1272 [01:35<00:00, 13.34it/s, epoch=2, errD=0.00443, errG=6.34]
100%|██████████| 1272/1272 [01:34<00:00, 13.43it/s, epoch=3, errD=0.054, errG=5.06]
100%|██████████| 1272/1272 [01:33<00:00, 13.66it/s, epoch=4, errD=0.795, errG=3.86]
Step 3: Wrapping the model¶
In order to wrap your model with any wrapper you need to pass in the model along with a sample input to your model. Here we are choosing the Bernoulli distibuition with p = 0.01 for our sample wrapper.
#import the Wrapper from capsa_torch
from capsa_torch import sample
from capsa_torch.sample.distribution import Bernoulli
#Wrap the generator model
netG = sample.Wrapper(distribution=Bernoulli(p=0.01))(netG)
The Generator is now wrapped and can return uncertainty outputs
Note¶
Most wrappers require re-training or finetuning. Sample is one of the wrappers that doesn’t require re-training or finetuning, however it will have better performance if it has been finetuned or trained. Read the wrapper documentations in order to pick the one that is suitable for your usecase.
Step 4: Testing & Evaluation¶
Once you have trained your wrapped model, you will get a risk value for every output to your model if return_risk = True.
#Generate some random noise
noise = torch.randn((64, nz, 1, 1), device=device)
#Get the generated images and associated risks from the wrapped model
fake_img, risk = netG(noise, return_risk = True)
#Plot the generated image and risk
def plot_risk(imgs, risk, index):
img = np.transpose(imgs[index].detach().cpu().numpy(),(1,2,0))
#normalize
img = (img-np.min(img))/(np.max(img)-np.min(img))
r = np.transpose(risk[index].detach().cpu().numpy(),(1,2,0))
r = (r-np.min(r))/(np.max(r)-np.min(r))
f, ax = plt.subplots(1, 2)
ax[0].imshow(img)
ax[1].imshow(r)
plot_risk(fake_img, risk, 0)
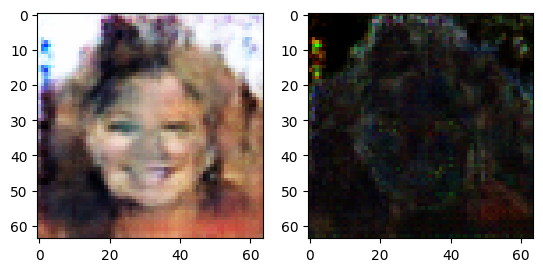
High uncertainty appears mostly at the edges of facial structures, indicating the model is more uncertain about its generating images at areas with fine structures. The uncertainty estimation can guide the training of GANs to achive higher accuracy, one example can be found here: https://arxiv.org/abs/2106.15542